Confidence Intervals
Probability estimation query Pr[…](<> q) yields a confidence interval (CI) for the probability of the state expression q being true with the confidence level of 1-α. For example, it could be [0.45, 0.55] (95% CI), or could be written as 0.5 ± 0.05 (95% CI), where ε=0.05 and α=0.05.
The frequentist interpretation of CI is that there exists a true probability that the state expression q is true and it is included in that confidence interval, but there is a risk α of making an error (the true probability being outside the confidence interval).
Chernoff-Hoeffding bound N=ln(2/α)/(2ε2) provides an intuition that the number of required samples (runs) N is inversely proportional to ε2 and proportional to the ln(1/α). This result assumes that the measurements are sampled from a continuous interval [0,1] which makes it overly conservative. For example, for α=0.05 and ε=0.05 it requires 738 runs irrespective of the actual probability. However, if the samples are constrained to either 0 or 1 and we observe a repetitive sequence of 30 successes we could conclude much earlier with [0.9,1] (95% CI) just by using a statistical rule of three.
Instead, UPPAAL uses Clopper-Pearson exact method for binomial distribution which samples from {0,1} and provides more precise bounds with fewer runs, especially when the probability is close to 0 or 1.
If the number of runs is not specified in the query, then the probability estimation uses Clopper-Pearson algorithm sequentially to determine when to stop generating the simulation runs thus allowing earlier termination. Therefore the number of runs is sensitive to α, ε and also the estimated probability itself. The α and ε parameters are controlled in the statistical parameters of engine options.
The following plots show the number of samples (runs) required to estimate the confidence interval using the exact method sequentially for a given α, ε and the true probability (estimating P>0.5 is symmetric to estimating 1-P):
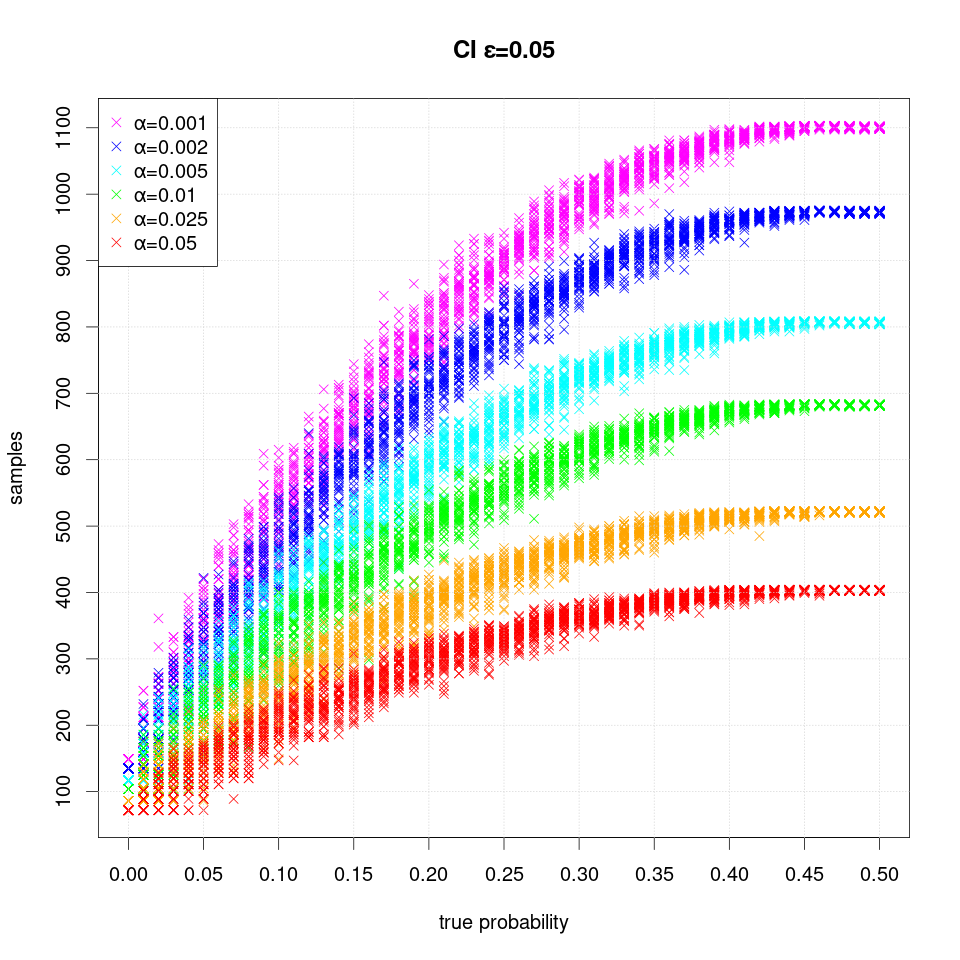 For example, for the default parameter values ε=0.05 and α=0.05 the sequential algorithm requires 411 — the highest number of samples (runs) — when the probability is close to 0.5, where the uncertainty is the highest. Whereas the algorithm cannot distinguish the true probabilities ≤ ε (0.05) and thus could terminate much earlier: after 72 runs. Note that the uncertainty of the required runs is the largest when the true probability is close to either 0 or 1.
For example, for the default parameter values ε=0.05 and α=0.05 the sequential algorithm requires 411 — the highest number of samples (runs) — when the probability is close to 0.5, where the uncertainty is the highest. Whereas the algorithm cannot distinguish the true probabilities ≤ ε (0.05) and thus could terminate much earlier: after 72 runs. Note that the uncertainty of the required runs is the largest when the true probability is close to either 0 or 1.
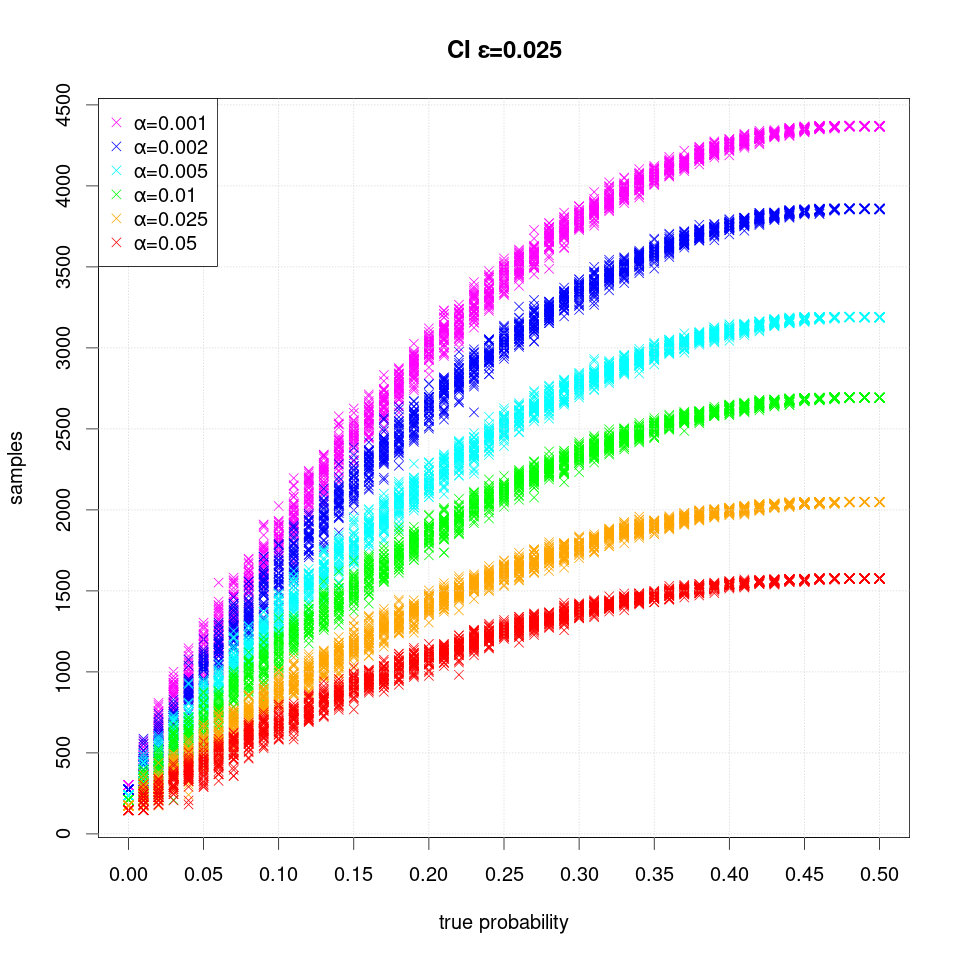
The following plot shows the number of samples (runs) required when the width of the interval is halved to ε=0.025:
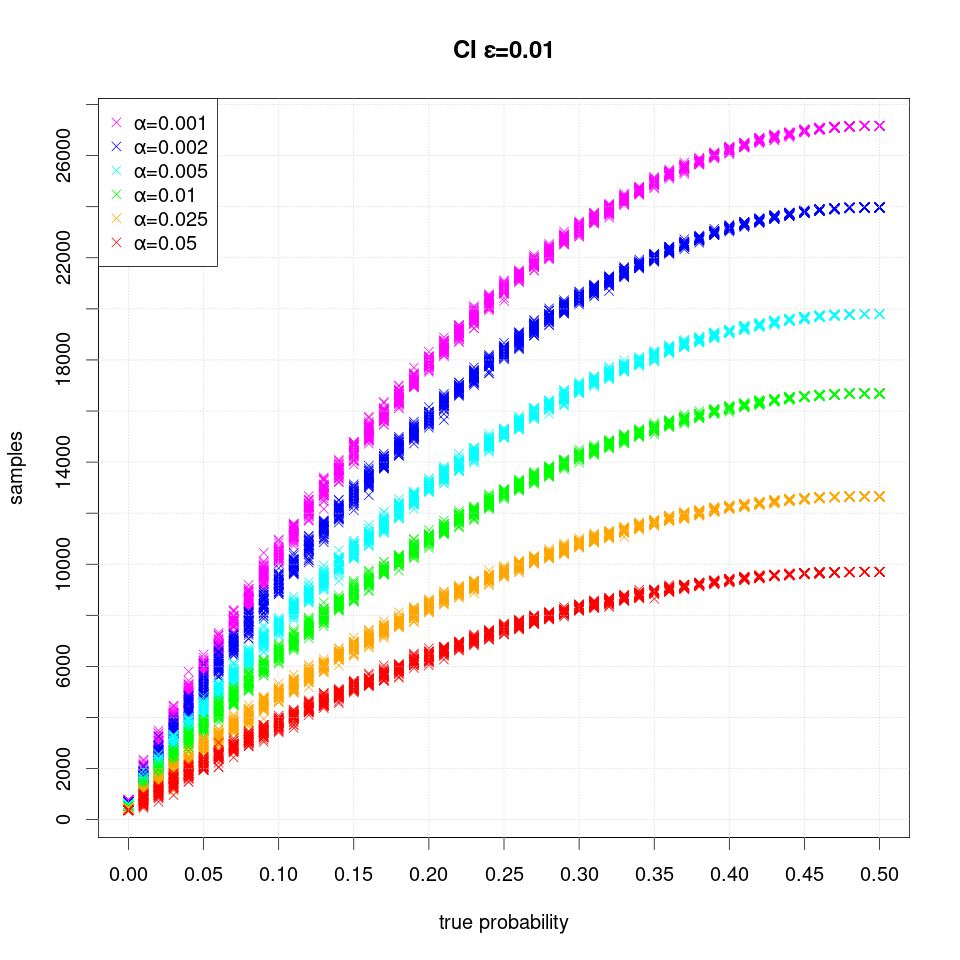
 The following plot shows the number of samples (runs) required when the width of the interval is even more narrow ε=0.01:
The following plot shows the number of samples (runs) required when the width of the interval is even more narrow ε=0.01:
The following series of plots demonstrates how the estimated confidence interval converges to the true probability P value as more samples are produced:
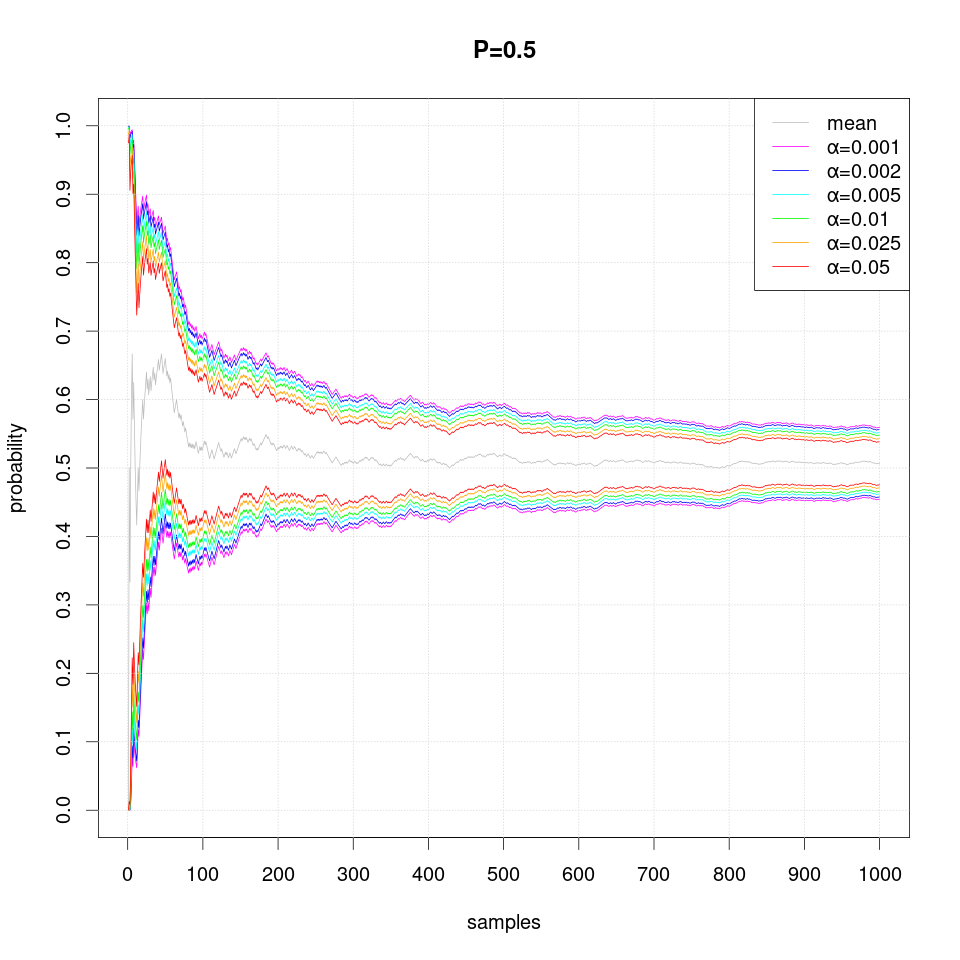
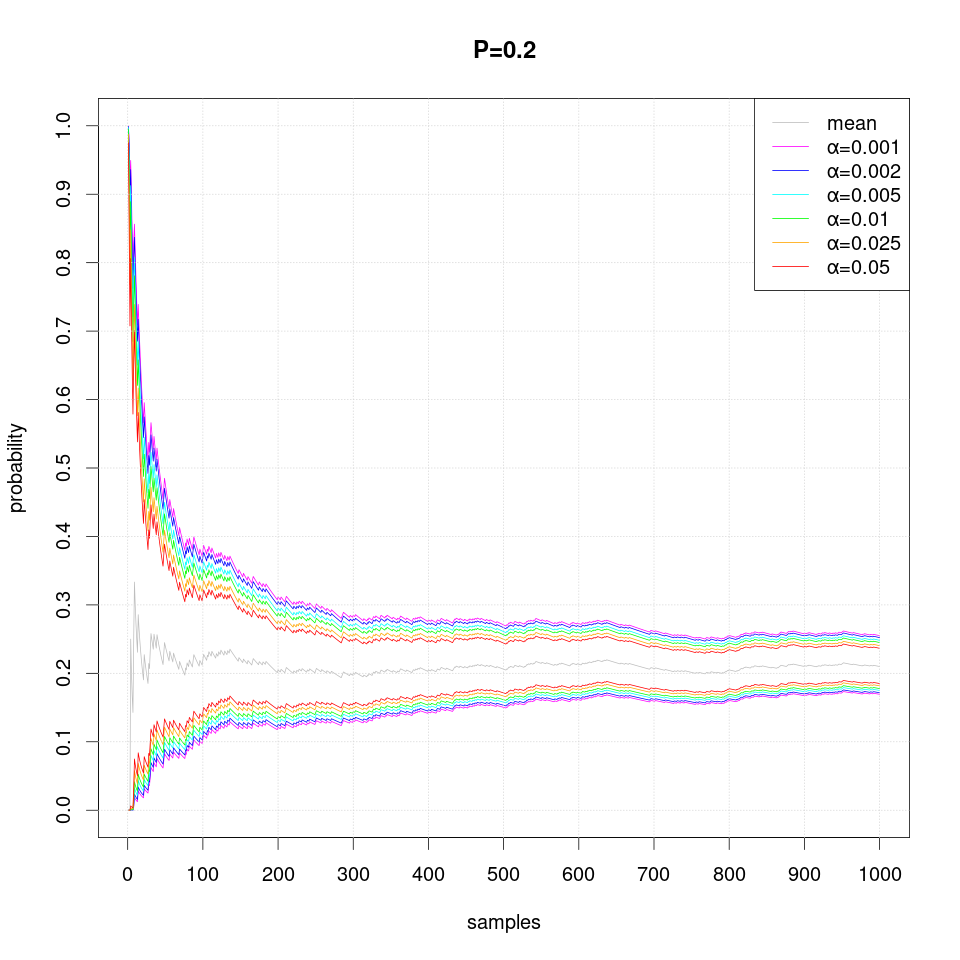
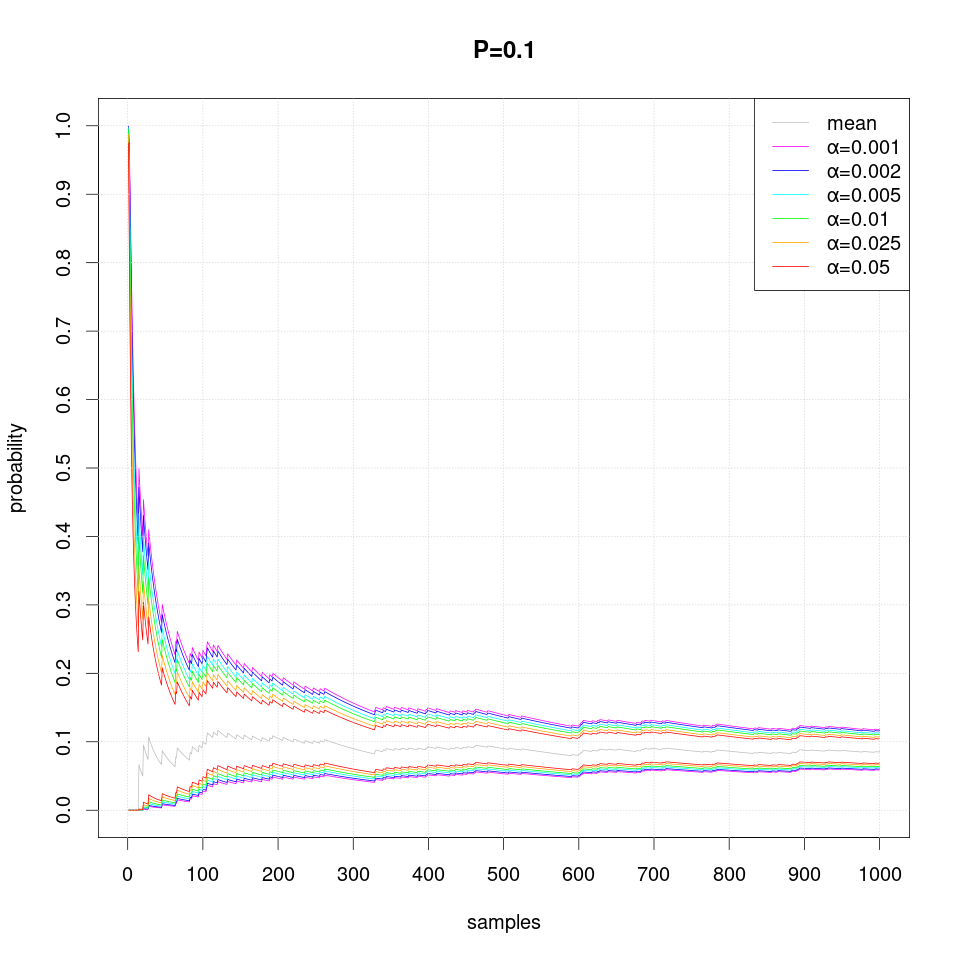
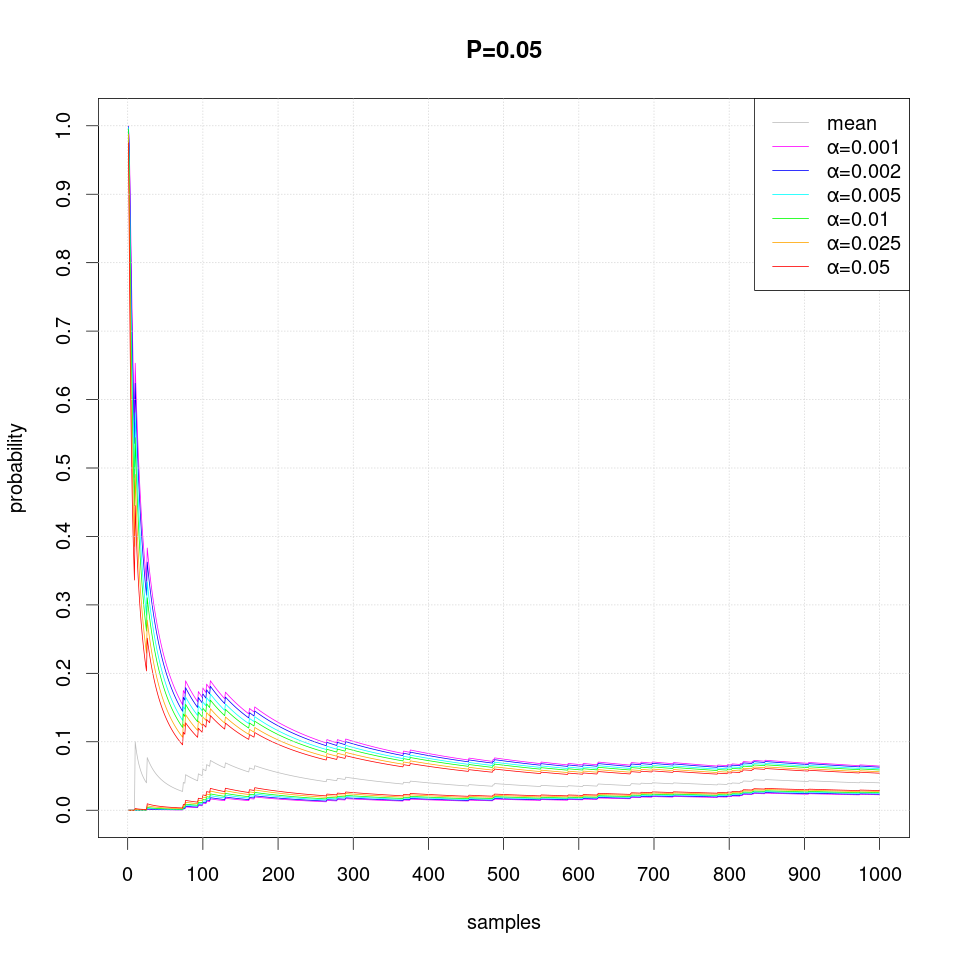
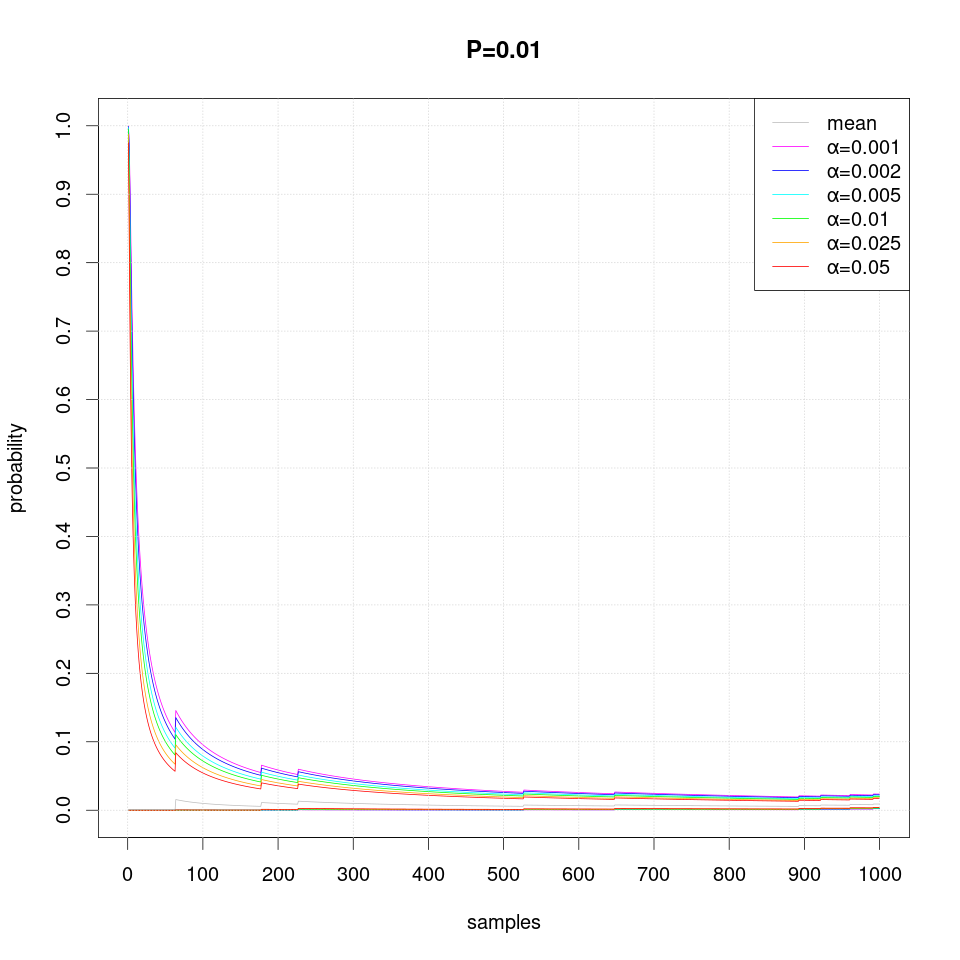
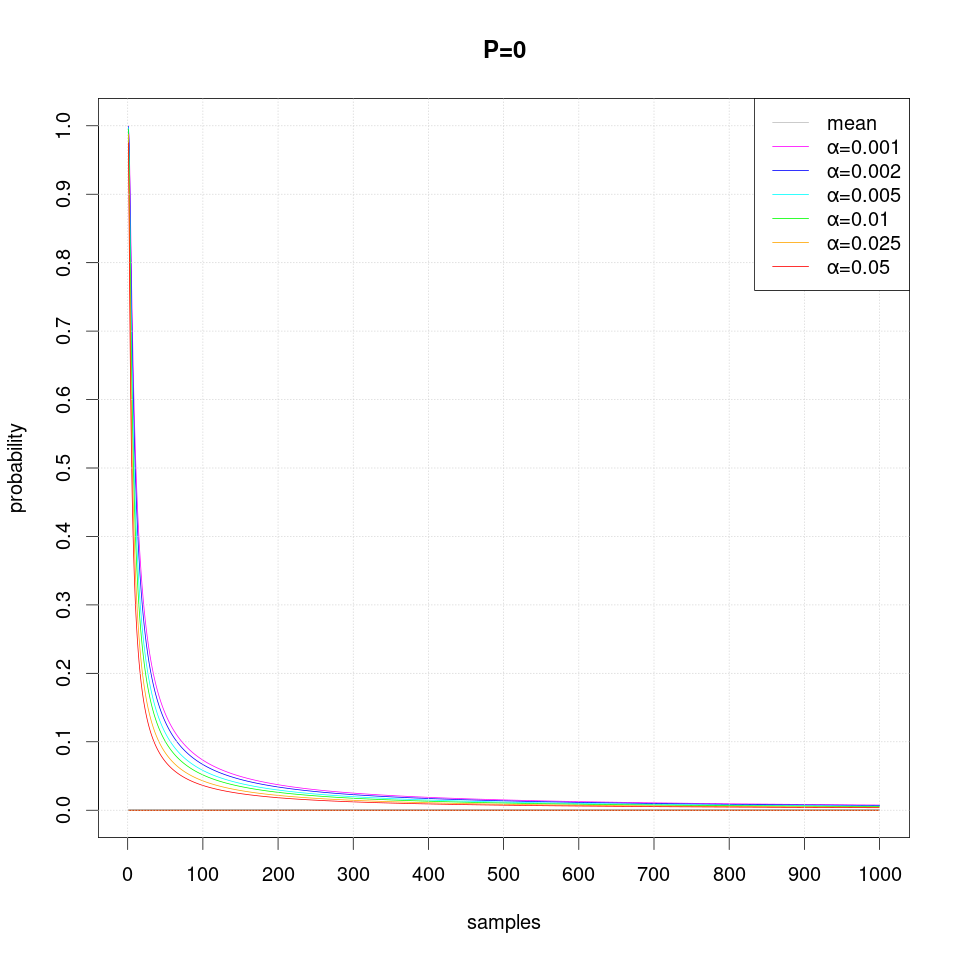
Note that occasionally the confidence intervals may overstep and thus exclude the true probability value, which should not happen more often than the specified level of significance α.
The following sequence of plots show how the width of the confidence intervals converges as more samples are produced:
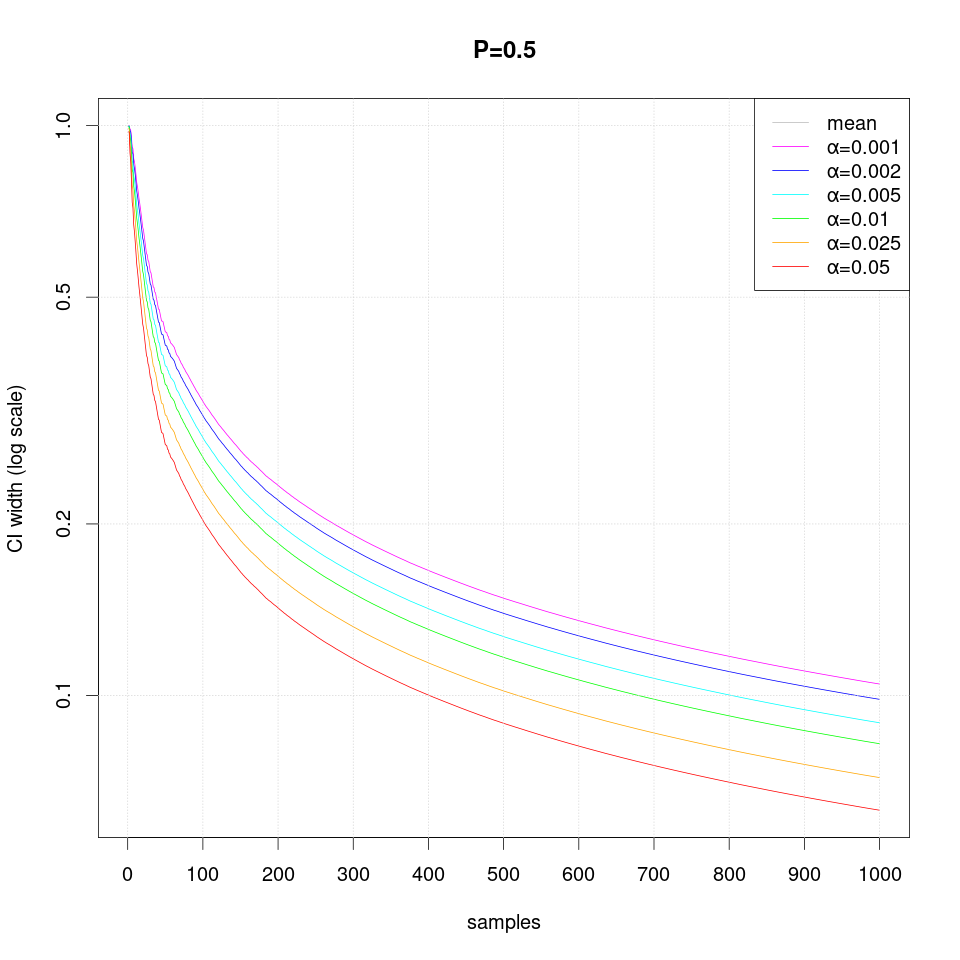
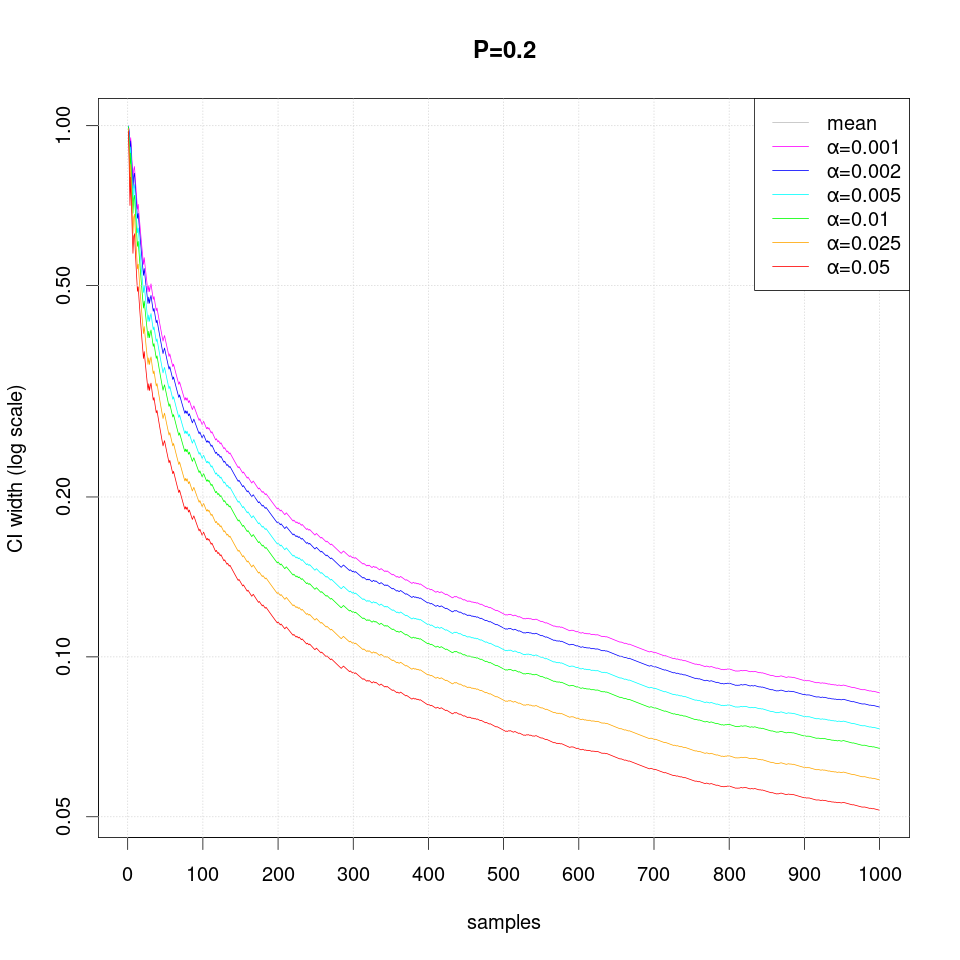
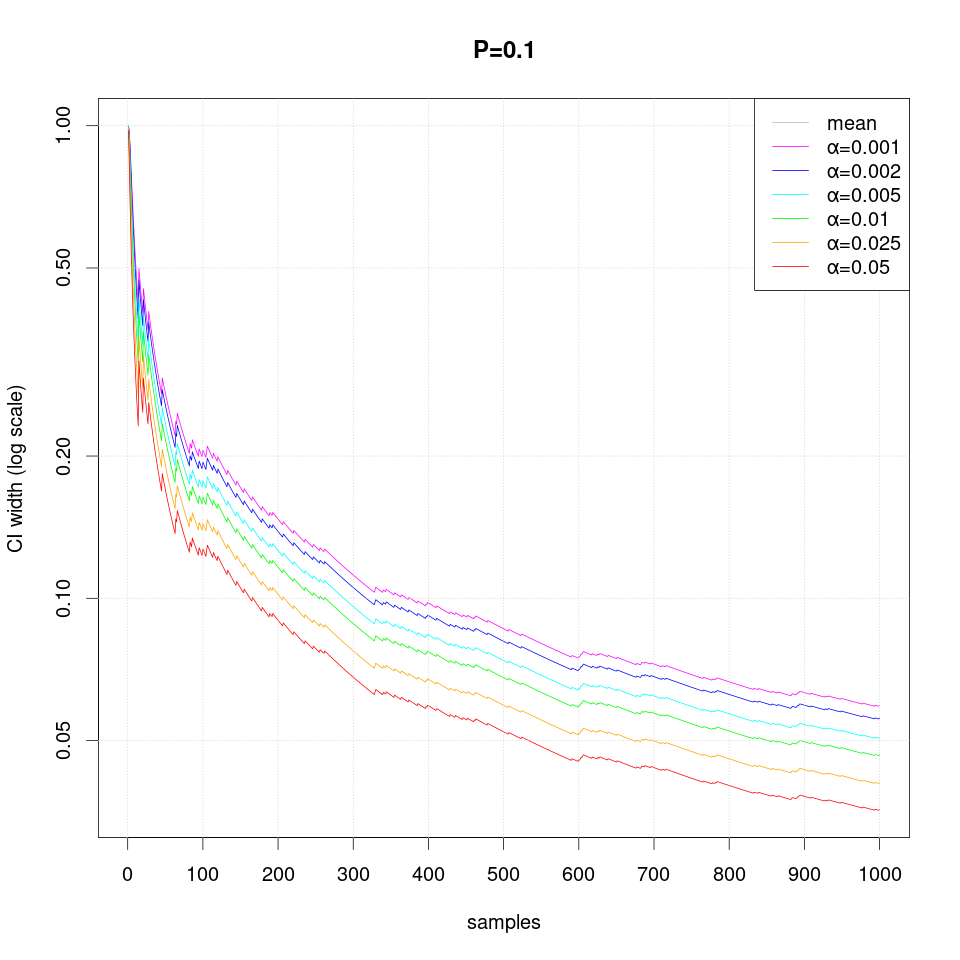
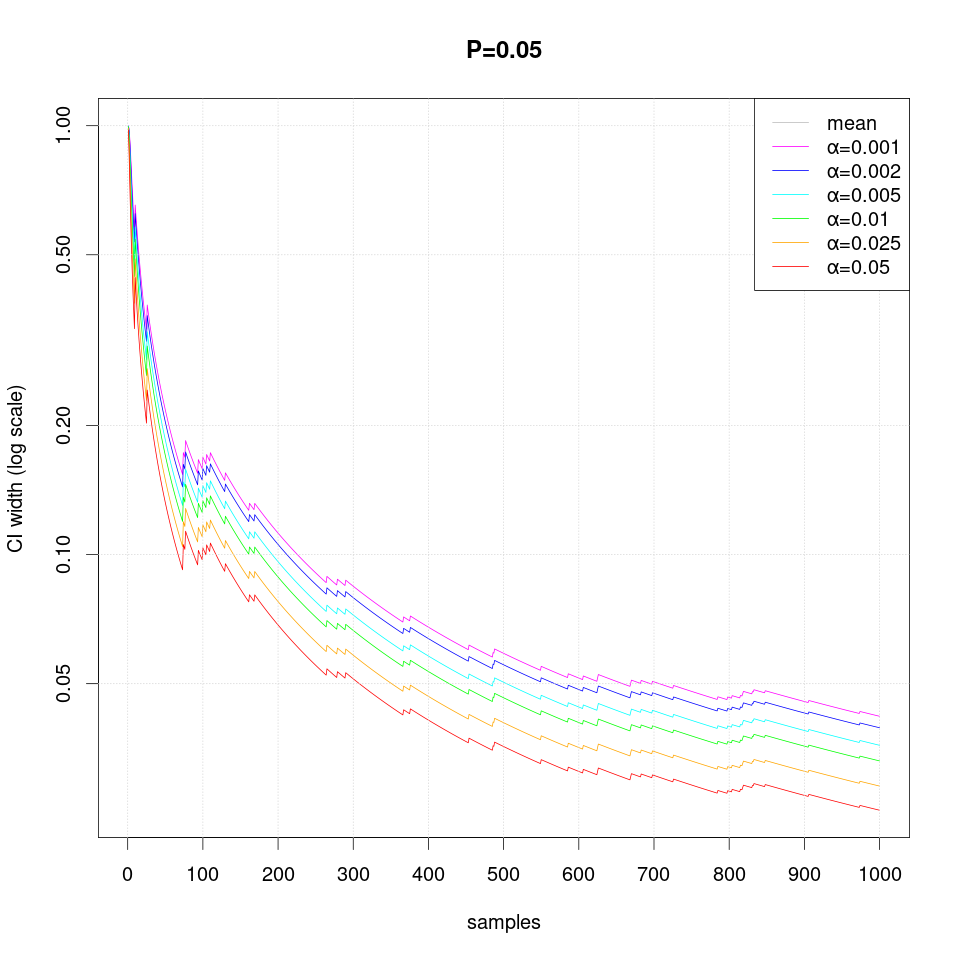
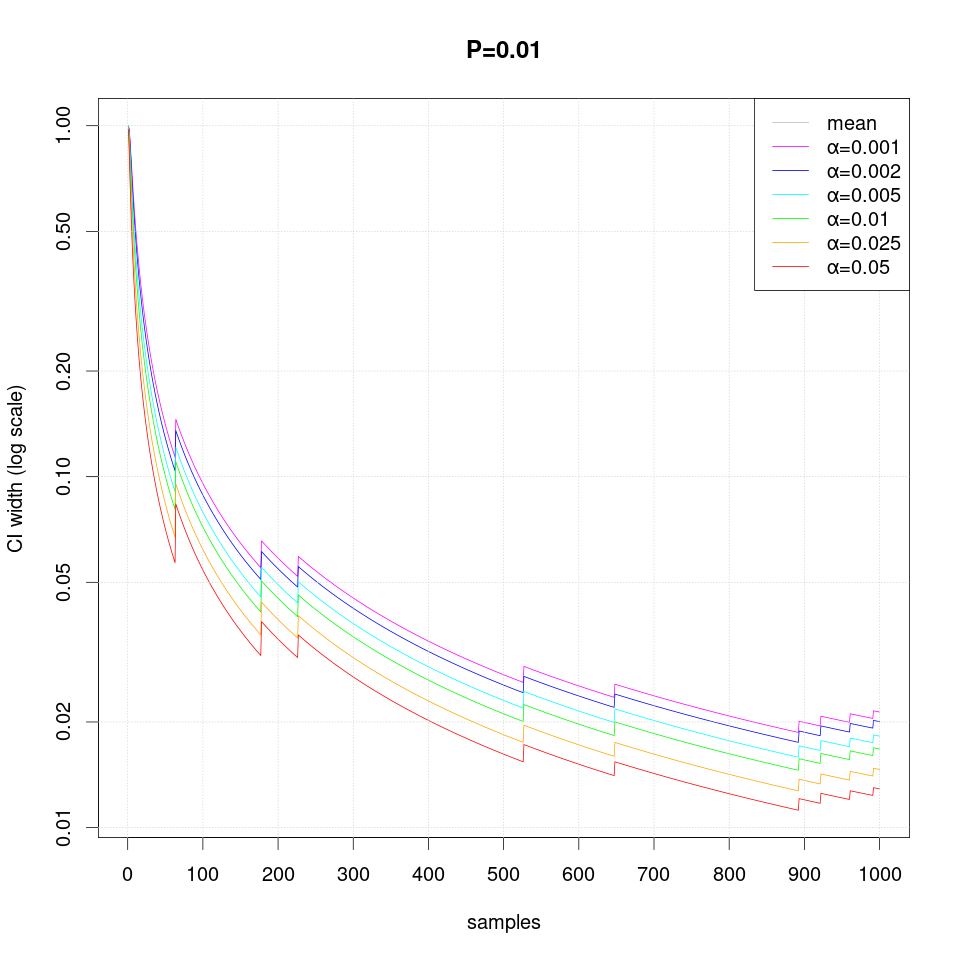
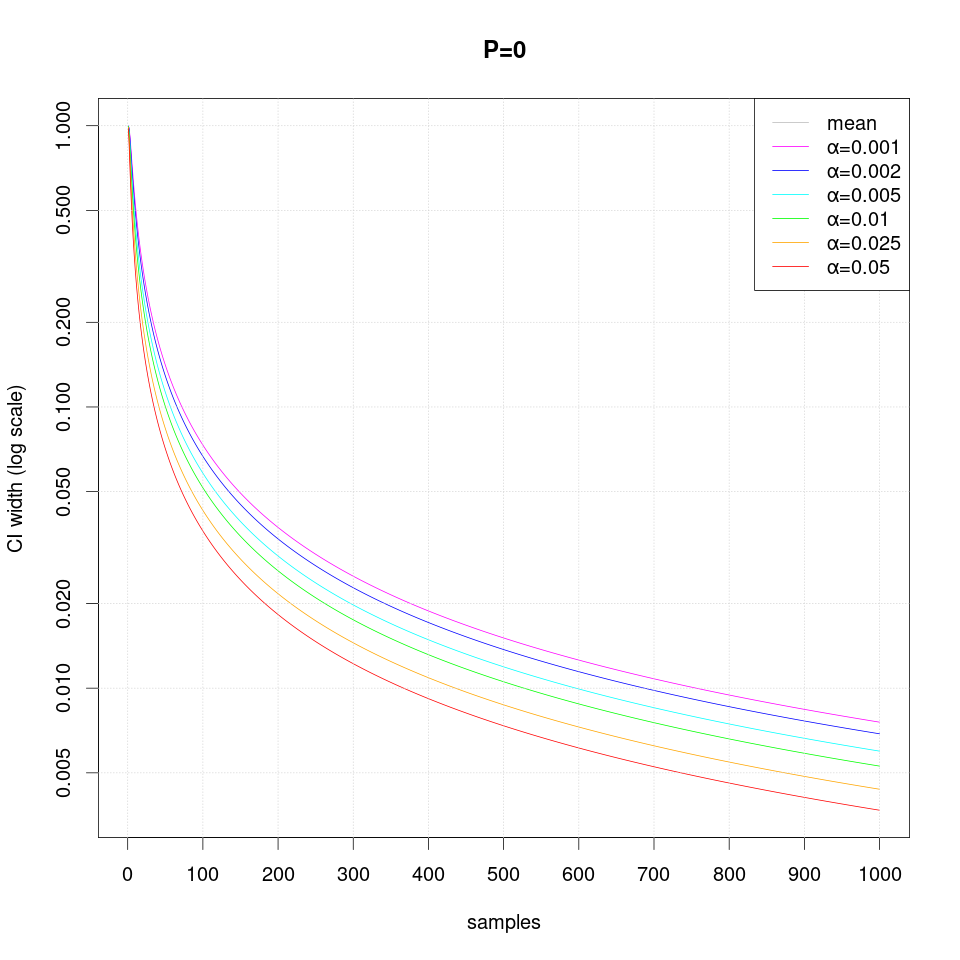
Note that in case of extreme probability value (close to 0 or 1, e.g. P=0.01), repeated observations are more likely and thus they may create false confidence that the probability is extreme (i.e. 0 or 1), but then a single differing observation may disturb the interval size greately and therefore more samples are required than just single sided interval.
Several sequential CI estimation algorithms for binomial proportion are described in the literature below.
Fixed-Width Sequential Confidence Intervals for a Proportion by Jesse Frey. In The American Statistician Volume 64, 2010 - Issue 3. doi:10.1198/tast.2010.09140
Exact Group Sequential Methods for Estimating a Binomial Proportion by Zhengjia Chen and Xinjia Chen. In: Journal of Probability and Statistics, 2013, special issue Adaptive and Sequential Methods for Clinical Trials. doi:10.1155/2013/603297